SPARF
Neural Radiance Fields from Sparse and Noisy Poses
SPARF enables realistic view synthesis from as few as 2 input images with noisy poses.
Abstract
Neural Radiance Field (NeRF) has recently emerged as a powerful representation to synthesize photorealistic novel views. While showing impressive performance, it relies on the availability of dense input views with highly accurate camera poses, thus limiting its application in real-world scenarios. In this work, we introduce Sparse Pose Adjusting Radiance Field (SPARF), to address the challenge of novel-view synthesis given only few wide-baseline input images (as low as 3) with noisy camera poses. Our approach exploits multi-view geometry constraints in order to jointly learn the NeRF and refine the camera poses. By relying on pixel matches extracted between the input views, our multi-view correspondence objective enforces the optimized scene and camera poses to converge to a global and geometrically accurate solution. Our depth consistency loss further encourages the reconstructed scene to be consistent from any viewpoint. Our approach sets a new state of the art in the sparse-view regime on multiple challenging datasets.
TL;DR: We include additional geometric constraints during the NeRF optimization to enable learning a meaningful geometry and rendering realistic novel views, given only 2 or 3 wide-baseline input views with noisy poses.
We are honored to be featured in the May edition of the Computer Vision News and in the CVPR special! Check out the articles. Big thanks to Ralph Anzarouth from Computer Vision News!
Teaser Video
Method Overview
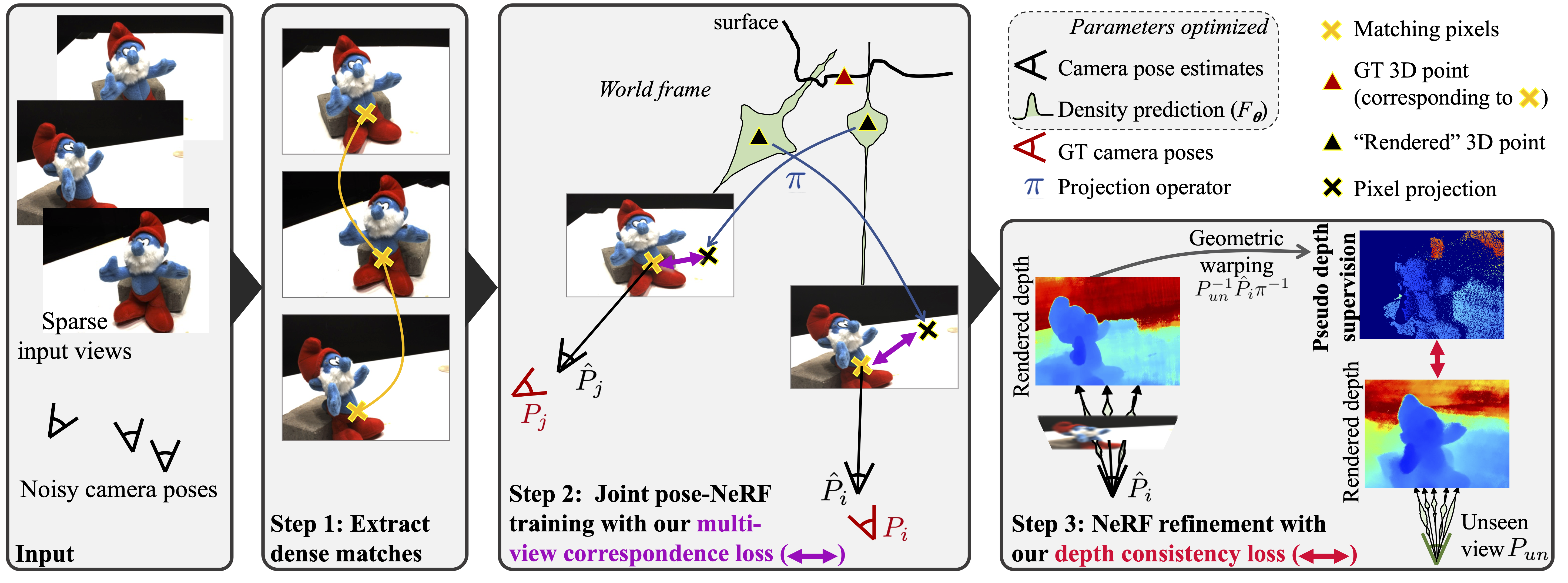
Most previous NeRF-based approaches for joint pose-NeRF training optimizes the reconstruction loss for a given set of input images. For sparse inputs, however, this leads to degenerate solutions. In this work, we propose SPARF, an approach for joint pose-NeRF training specifically designed to tackle the challenging scenario of few input images with noisy camera pose estimates. We first rely on a pretrained dense correspondence network to extract matches between the training views (step 1). Our multi-view correspondence loss (step 2) minimizes the re-projection error between matches, i.e. it enforces each pixel of a particular training view to project to its matching pixel in another training view. We use the rendered NeRF depth and the current pose estimates to backproject each pixel in 3D space. This constraint hence encourages the learned scene and pose estimates to converge to a global and accurate geometric solution, consistent across all training views. Our depth consistency loss (step 3) further uses the rendered depths from the training viewpoints to create pseudo-depth supervision for unseen viewpoints, thereby encouraging the reconstructed scene to be consistent from any direction.
Results
View Synthesis on DTU from 3 Input Views with Noisy Camera Poses
DTU is composed of complex object-centric scenes, with wide-baseline views spanning a half-hemisphere. We only have access to 3 input views, along with initial noisy camera poses. We create these initial poses by synthetically perturbing the ground-truth camera poses with 15% of Gaussian noise. This leads to an initial rotation error of 15, and an initial translation error equal to 15% of the scene scale. Our approach SPARF is the only one producing realistic novel-view renderings with a meaningful geometry!
View Synthesis on LLFF from 3 Input Views with Noisy Camera Poses
LLFF is a forward-facing dataset, depicting complex indoor and outdoor scenes. We only have access to 3 input views, along with initial identity poses. As before, our approach SPARF leads to much better-quality novel-view renderings, and learns an accurate geometry.
View Synthesis on Replica from 3 Input Views with Noisy Camera Poses
Replica is a non-forward facing dataset, depicting indoor scenes. We only have access to 3 input views, along with noisy poses initialized by COLMAP. The scene geometry rendered by our approach SPARF is more accurate and realistic than competitor works BARF, DS-NeRF and SCNeRF. It contains significantly less floaters and inconsistencies.
Citation
If you want to cite our work, please use:
@InProceedings{sparf2023,
title={SPARF: Neural Radiance Fields from Sparse and Noisy Poses},
author = {Truong, Prune and Rakotosaona, Marie-Julie and Manhardt, Fabian and Tombari, Federico},
publisher = {{IEEE/CVF} Conference on Computer Vision and Pattern Recognition, {CVPR}},
year = {2023}